 Sometimes you need to work with texts that only come printed. Or you may want to insert parts of a book into a document. This is where OCR comes in: scanning a printed text and converting it into an editable text file.
Sometimes you need to work with texts that only come printed. Or you may want to insert parts of a book into a document. This is where OCR comes in: scanning a printed text and converting it into an editable text file.
Of course there is proprietary software to do the job, e.g. ABBYY FineReader. But if you only need this occasionally, you do not want to spend the (lots of) money it costs. And, of course, very often these applications are not for Linux anyway.
Luckily there are relatively good open-source alternatives, including Linux applications.
The best open-source solution for OCR is Tesseract. Originally a commercial enterprise by Hewlett Packard, but the project was open-sourced in 2005 and is in active development by Google since 2006. It covers about 60 different languages, including Asian and Semitic. Another good tool is Cuneiform, of once Russian origin. Both can be installed directly from the Ubuntu main repositories, either in your package manager or software center, or in a terminal:
sudo apt-get update sudo apt-get install tesseract-ocr cuneiform
Tesseract can be used directly from the command-line. Open a terminal and type man tesseract for instructions. However, that is not really the user-friendly way.
Enters OCRfeeder for Ubuntu platforms with its easy GUI. It uses Tesseract or Cuneiform as ‘engine’, or, if you insist, also older tools like Ocrad or GOCR. Neither of the latter two appear to be actively maintained now, but they do still work. Nevertheless, just set Tesseract as your default engine.
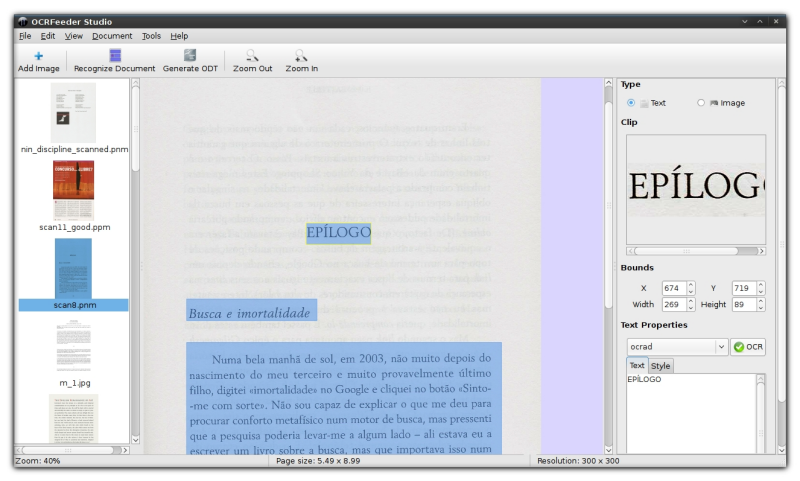 OCRfeeder wants you to work left-to-right across its main window. First you add a source document to the left, either an image (PNG, JPG, TIFF etc.), a PDF, or a whole folder of these. You can also import an image directly from your scanner. If the original is a bit distorted, or the background is blotted, crumpled or something, OCRfeeder offers you two options to improve the quality: deskew and unpaper.
OCRfeeder wants you to work left-to-right across its main window. First you add a source document to the left, either an image (PNG, JPG, TIFF etc.), a PDF, or a whole folder of these. You can also import an image directly from your scanner. If the original is a bit distorted, or the background is blotted, crumpled or something, OCRfeeder offers you two options to improve the quality: deskew and unpaper.
Next click the ‘Recognize Document’ button to process the source. To finish the action there is the seemingly easy option of clicking the ‘Generate ODT’ button. However, that will produce an ODT file with the text in frames, which is a bit awkward to work on. A more useful option is to go to File > Export and choose ‘Plain Text’ as your format. Before you do, you may want to edit the processed text in OCRfeeder’s editor, below on the right side.
That’s it. Now you can insert your OCR-ed source into your text document and add exactly the lay-out you want it to have.
Further information can be found from the Help menu. Or, for those not afraid of German ‘Gründlichkeit’, explore the dedicated Wiki page.
Minor glitch: since OCRfeeder is typically a GNOME application, some things do not work well on a KDE desktop like mine, e.g. remembering window size and position. But I can live with that.